728x90
▷ 학습/테스트 데이터 세트 분리
- 데이터 세트로만 학습한 후 예측하기 ( 예측 정화도 : 100% )
# 관련 모듈 import 하기
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 붓꽃 데이터 세트 로드하기
iris = load_iris()
# DecisionTreeClassifier 객체 생성하기
dt_clf = DecisionTreeClassifier()
# iris.data : feature 만으로 된 데이터
train_data = iris.data
# iris.target: label 데이터
train_label= iris.target
# 학습 수행하기
dt_clf.fit(train_data, train_label)
# 학습 데이터 세트로 예측 수행하기
pred = dt_clf.predict(train_data)
print(f'예측 정확도 : {accuracy_score(iris.target,pred)}')
- 학습 데이터 세트와 테스트 데이터 세트를 분리한 후 예측하기 ( 예측 정확도 : 95.5% )
# 관련 모듈 import 하기
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# DecisionTreeClassifier 객체 생성하기
dt_clf = DecisionTreeClassifier()
# 붓꽃 데이터 세트 로드하기
iris = load_iris()
# 학습 데이터 세트와 테스트 데이터 세트 분리하기
x_train,x_test,y_train,y_test = train_test_split(iris.data,
iris.target,
test_size=0.3,
random_state=None)
# 학습 수행하기
dt_clf.fit(x_train,y_train)
# 학습 데이터 세트로 예측 수행하기
pred = dt_clf.predict(x_test)
print(f'예측 정확도 : {accuracy_score(y_test,pred)}')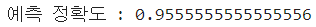
▷교차 검증
: 데이터 편중을 막기 위해 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것
① K Fold 교차 검증 ( 평균 정확도 : 90% )
: K 개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴트 세트에 학습과 검증 평가를 반복적으로 수행하는 방법
# 관련 모듈 import 하기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
# 붓꽃 데이터 세트 로드하기
iris = load_iris()
# iris.data : feature 만으로 된 데이터
features = iris.data
# iris.target: label 데이터
labels = iris.target
# DecisionTreeClassifier 객체 생성하기
dt_clf = DecisionTreeClassifier(random_state = 156)
# 5개의 폴드 세트로 분리하는 KFold 객체 생성
kfold = KFold(n_splits = 5)
# 폴드 세트별 정확도를 담을 리스트 객체 생성
cv_accuracy = []
n_iter = 0
# KFold 객체의 split() 를 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 array로 변환
for train_index,test_index in kfold.split(features):
# kfold.split()으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
x_train,x_test = features[train_index],features[test_index]
y_train,y_test = label[train_index],label[test_index]
# 학습하기
dt_clf.fit(x_train,y_train)
# 예측하기
pred = dt_clf.predict(x_test)
n_iter += 1
# 반복시마다 정확도 측정하기
accuracy = np.round(accuracy_score(y_test,pred),4)
# 건수만 확인하기 위해서 index 값 확인
train_size=x_train.shape[0]
test_size=x_test.shape[0]
print(f'{n_iter} 교차검증정확도 : {accuracy} , 학습 데이터 크기 : {train_size} , 검증 데이터 크기 : {test_size}')
print(f'검증 데이터 인덱스 : {test_index}')
cv_accuracy.append(accuracy)
print(f'평균 정확도 : {np.mean(cv_accuracy)}')
② Stratified K Fold ( 평균 정확도 : 96.6% )
: 불균형한 분포도를 가진 레이블 데이터 집합(특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것)을 위한 K Fold 방식
# 관련 모듈 import 하기
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits = 3,shuffle = False)
n_iter = 0
cv_accuracy=[]
# StratifiedKFold의 split() 호출시 반드시 레이블 데이터 세트도 추가 입력 필요
for train_index,test_index in skfold.split(iris.data,iris.target):
# split() 으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
x_train,x_test = iris.data[train_index],iris.data[test_index]
y_train,y_test = iris.target[train_index],iris.target[test_index]
# 학습하기
dt_clf.fit(x_train,y_train)
# 예측하기
pred = dt_clf.predict(x_test)
# 반복 시마다 정확도 측정하기
n_iter += 1
accuracy = np.round(accuracy_score(y_test,pred),4)
# 건수만 확인하기 위해서 index 값 확인
train_size=x_train.shape[0]
test_size=x_test.shape[0]
print(f'{n_iter} 교차검증정확도 : {accuracy} , 학습 데이터 크기 : {train_size} , 검증 데이터 크기 : {test_size}')
print(f'검증 데이터 인덱스 : {test_index}')
cv_accuracy.append(accuracy)
print(f'평균 정확도 : {np.mean(cv_accuracy)}')
③ cross_val_score() ( 평균 정확도 : 96.6% )
# 관련 모듈 import 하기
from sklearn.model_selection import cross_val_score
# 붓꽃 데이터 불러오기
iris_data = load_iris()
# DecisionTreeClassifier 객체 생성하기
dt_clf = DecisionTreeClassifier(random_state=156)
# cross_val_score() 검증 수행하기
# cv : 교차 검증 폴드 수 , scoring : 예측 성능 평가 지표
cross_val_score(dt_clf,
iris.data,
iris.target,
cv=3,
scoring='accuracy',
verbose=0)
print(f'평균 검증 정확도 : {np.mean(scores):.4f}')
④ GridSearchCV ( 예측 정확도 : 96.6% )
# 관련 모듈 import 하기
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
import pandas as pd
# 데이터를 로딩하기
iris = load_iris()
# 학습데이터와 테스트 데이터 분리하기
x_train,x_test,y_train,y_test = train_test_split(iris.data,
iris.target,
test_size=0.2,
random_state=121)
dtree = DecisionTreeClassifier()
# 파라미터를 딕셔너리 형태로 설정하기
param = {'max_depth':[1,2,3],
'min_samples_split':[2,3]}
# param_grid의 하이퍼 파라미터를 3개의 train, test set fold로 나누어 테스트 수행 설정하기
# refit =True가 default 값, True 이면 가장 좋은 파라미터 설정으로 재학습시킴.
grid_tree = GridSearchCV(dtree,
param_grid=param,
cv=3,
refit=True)
# 붓꽃 학습 데이터로 param_grid 의 하이퍼 파라미터를 순차적으로 학습/평가하기
grid_tree.fit(x_train,y_train)
# GridSearchCV 예측하기
pred = grid_tree.predict(x_test)
# GridSearchCV 평가하기
accuracy = accuracy_score(y_test,pred)
print(f'예측 정확도 : {accuracy:.4f}')
'개념정리 > 머신러닝' 카테고리의 다른 글
| 머신러닝 - 오차행렬 , 정확도 , 정밀도, 재현율 (0) | 2023.05.15 |
|---|---|
| 머신러닝 - 데이터 전처리 (데이터 인코딩 & 피처 스케일링과 정규화) (1) | 2023.05.13 |
| 머신러닝 - 사이킷런으로 수행하는 타이타닉 생존자 예측 (0) | 2023.05.11 |
| 머신러닝 - scikit-learn(사이킷런) & 붓꽃 품종 예측하기 (0) | 2023.05.09 |
| ▷ Python 머신러닝 - 지도학습 개념정리 (0) | 2023.03.23 |



